DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。下面我们就对DBSCAN算法的原理做一个总结。
TF-IDF原理
XGBoost完全指南
原文地址:Complete Guide to Parameter Tuning in XGBoost (with codes in Python)
XGBoost(eXtreme Gradient Boosting)是Gradient Boosting算法的一个优化的版本。因为我在前一篇文章,基于Python的Gradient Boosting算法参数调整完全指南,里面已经涵盖了Gradient Boosting算法的很多细节了。我强烈建议大家在读本篇文章之前,把那篇文章好好读一遍。它会帮助你对Boosting算法有一个宏观的理解,同时也会对GBM的参数调整有更好的体会。
LightGBM使用
xgboost的出现,让数据民工们告别了传统的机器学习算法们:RF、GBM、SVM、LASSO……..。微软推出了一个新的boosting框架,想要挑战xgboost的江湖地位。
顾名思义,lightGBM包含两个关键点:light即轻量级,GBM 梯度提升机。
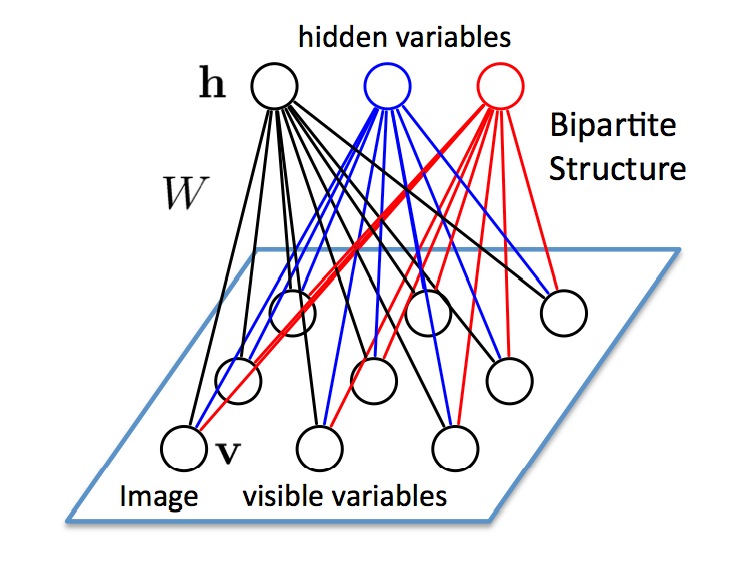
Restricted Boltzmann Machine
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是G.Hinton教授的一宝。Hinton教授是深度学习的开山鼻祖,也正是他在2006年的关于深度信念网络DBN的工作,以及逐层预训练的训练方法,开启了深度学习的序章。其中,DBN中在层间的预训练就采用了RBM算法模型。RBM是一种无向图模型,也是一种神经网络模型。
OPTICS算法基础
在前面介绍的DBSCAN算法中,有两个初始参数E(邻域半径)和minPts(E邻域最小点数)需要用户手动设置输入,并且聚类的类簇结果对这两个参数的取值非常敏感,不同的取值将产生不同的聚类结果,其实这也是大多数其他需要初始化参数聚类算法的弊端。